| World of VISL > Treebanks | VISL - Visual Interactive Syntax Learning |
|
|
|||||
|
|
VISL
produces two kinds of treebanks, (a) small, pedagogically
structured teaching treebanks with selected sentences, and (b) large
treebanks over running text, or treebanks with a randomized inventory
of real corpus sentences. In all, 22 teaching languages and 5 research
languages are covered. While teaching treebanks will be largely
hand-made, research corpora are built with automatic parsers, usually
using a hybrid 2-stage system involving (1) Constraint Grammar analysis
and (2) PSG or dependency tree transformation. The resulting analyses
are then manually revised by VISL linguists or students.
Experimentally, so-called "jungle" treebanks are built, providing
extensive data, but without revision.
Research Treebanks and search interfaces:
- Arboretum (Danish treebanks) - Floresta sintá[c]tica(Portuguese treebanks) - L'Arboratoire (French treebanks) - Arborest (Estonian treebanks) - Corpuseye (search interface overview) - Corpus inventory (list of corpora, sources and sizes) VISL treebank manuals: - Cafeteria (VISL Category labelling principles) - Treebank formalism (Treebank design principles) - Category definitions(Danish examples) - Morphological categories (Terms and abbreviations) Treebank tools - Consistency checker (VISL format) |
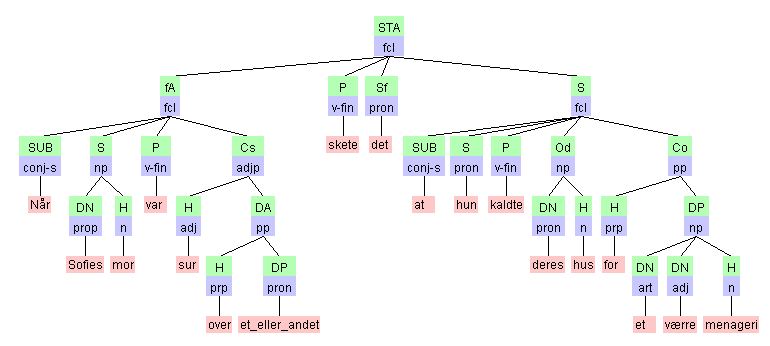
The graphical format:^
VISL's java-based
tree-visualiser will represent syntactic trees in an
interactive interface, allowing both step-by-step inspection and
manipulation ("rebuilding" and "retagging") of the tree. Each
constituent is represented as a node containing both form and function
information (e.g. Od:pron = a direct object, which is a pronoun). Trees
can be manipulated in 3 ways:
In evaluation-mode the java-program will keep count with your error rate, as well as provide hints and explanations along the way.

The source format:^
Internally, for format
filtering, searching and manual revision, trees
are stored in the VISL-format, as "horizontal" trees with a separate
line for each terminal or non-terminal node, with indentation marking
depth. A constituent's daughters will thus be listed below the mother
node, with an indentation level increased by 1. Cf. the example from
"The World of Sophie" below:
VISL constituent trees
are
built from Constraint Grammar parser's flat dependency output using a
function-based PSG and VISL's open source psg-compiler. Treebank
revision is performed first at CG-level, and again after
tree-generation, drawing robustness from the CG-system and depth from
the PSG-grammar.
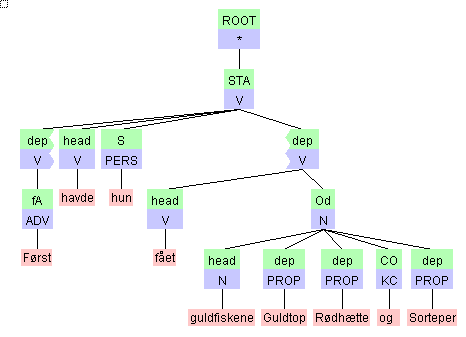
VISL dependency trees^
VISL dependency trees are constructed directly from
word based CG input using structural
transformation filters based on Prolog (S. Harder) or Perl (E. Bick).
In source annotation, the result is ordinary CG enriched with token and
head id's. =4:2
or #4->2
on a tag line means that
the token in question (number 4) attaches to head token number 2. There
are two modules that can be used to add dependency numbering links to
CG input.
<s_id="sofie-da43">
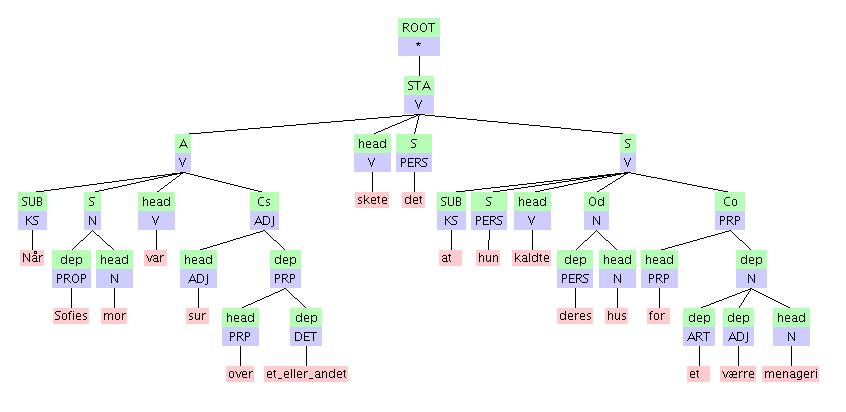

TIGER exchange format^
:
This is the treebank exchange format agreed upon by the Nordic
Treebank Network, allowing free
data exchange and the use of tools
developed by the international TIGER
project
community. VISL constituent trees can be filtered into TIGER
constituent format using the program visl2tiger.pl.
In TIGER format, edge labels contain the original syntactic function
tags, and the (non-teminal) cat
category contains phrase and
clause forms (graphical
example).
<s
id="s43" ref="sofie-da43" source="Sofie-da"
forest="5/7" text="Når Sofies mor var sur over et eller
andet,
skete det at hun kaldte deres hus for et værre menageri.
">
<graph root="s43_500">
<terminals>
<t
id="s43_1" word="Når"
lemma="når" pos="conj-s"
morph="--" extra="--"/>
<t
id="s43_2" word="Sofies"
lemma="Sofie" pos="prop" morph="GEN"
extra="hum"/>
<t
id="s43_3" word="mor"
lemma="mor" pos="n" morph="UTR S IDF NOM"
extra="--"/>
<t
id="s43_4" word="var"
lemma="være" pos="v-fin" morph="IMPF
AKT" extra="--"/>
<t
id="s43_5" word="sur"
lemma="sur" pos="adj" morph="UTR S IDF NOM"
extra="--"/>
<t
id="s43_6" word="over"
lemma="over" pos="prp" morph="--"
extra="--"/>
<t
id="s43_7" word="et_eller_andet"
lemma="en_eller_anden"
pos="pron-indef" morph="NEU S NOM" extra="--"/>
<t
id="s43_8" word="skete"
lemma="ske" pos="v-fin" morph="IMPF AKT"
extra="--"/>
<t
id="s43_9" word="det"
lemma="den" pos="pron-pers" morph="NEU 3S NOM"
extra="--"/>
<t
id="s43_10" word="at"
lemma="at" pos="conj-s" morph="--"
extra="--"/>
<t
id="s43_11" word="hun"
lemma="hun" pos="pron-pers" morph="UTR 3S NOM"
extra="--"/>
<t
id="s43_12" word="kaldte"
lemma="kalde" pos="v-fin" morph="IMPF AKT"
extra="--"/>
<t
id="s43_13" word="deres"
lemma="de" pos="pron-poss" morph="--"
extra="--"/>
<t
id="s43_14" word="hus"
lemma="hus" pos="n" morph="NEU S IDF NOM"
extra="--"/>
<t
id="s43_15" word="for"
lemma="for" pos="prp" morph="--"
extra="--"/>
<t
id="s43_16" word="et"
lemma="en" pos="art" morph="NEU S IDF"
extra="--"/>
<t
id="s43_17" word="værre"
lemma="dårlig" pos="adj"
morph="COM nG nN nD NOM" extra="--"/>
<t
id="s43_18" word="menageri"
lemma="menageri" pos="n" morph="NEU S IDF
NOM" extra="--"/>
</terminals>
<nonterminals>
<nt
id="s43_500" cat="s">
<edge
label="STA"
idref="s43_501"/>
</nt>
<nt
id="s43_501" cat="fcl">
<edge
label="fA"
idref="s43_502"/>
<edge
label="P"
idref="s43_8"/>
<edge
label="Sf"
idref="s43_9"/>
<edge
label="S"
idref="s43_506"/>
</nt>
<nt
id="s43_502" cat="fcl">
<edge
label="SUB"
idref="s43_1"/>
<edge
label="S"
idref="s43_503"/>
<edge
label="P"
idref="s43_4"/>
<edge
label="Cs"
idref="s43_504"/>
</nt>
<nt
id="s43_503" cat="np">
<edge
label="DN"
idref="s43_2"/>
<edge
label="H"
idref="s43_3"/>
</nt>
<nt
id="s43_504" cat="adjp">
<edge
label="H"
idref="s43_5"/>
<edge
label="DA"
idref="s43_505"/>
</nt>
<nt
id="s43_505" cat="pp">
<edge
label="H"
idref="s43_6"/>
<edge
label="DP"
idref="s43_7"/>
</nt>
<nt
id="s43_506" cat="fcl">
<edge
label="SUB"
idref="s43_10"/>
<edge
label="S"
idref="s43_11"/>
<edge
label="P"
idref="s43_12"/>
<edge
label="Od"
idref="s43_507"/>
<edge
label="Co"
idref="s43_508"/>
</nt>
<nt
id="s43_507" cat="np">
<edge
label="DN"
idref="s43_13"/>
<edge
label="H"
idref="s43_14"/>
</nt>
<nt
id="s43_508" cat="pp">
<edge
label="H"
idref="s43_15"/>
<edge
label="DP"
idref="s43_509"/>
</nt>
<nt
id="s43_509" cat="np">
<edge
label="DN"
idref="s43_16"/>
<edge
label="DN"
idref="s43_17"/>
<edge
label="H"
idref="s43_18"/>
</nt>
</nonterminals>
</graph>
</s>
TIGER dependency format:^
This format is derived from
TIGER constituent trees using a special
Perl program, called tiger2dep.pl.
In this format, word-terminals are "identified" with their dependency
node by using the empty edge label '--'.
<s
id="s43"
ref="sofie-da43" source="Sofie-da" forest="5/7" text="Når
Sofies
mor var sur over et eller andet, skete det at hun kaldte deres hus for
et værre menageri. ">
<graph root="s43_500">
<terminals>
<t
id="s43_1" word="Når"
lemma="når" pos="conj-s"
morph="--" extra="--"/>
<t
id="s43_2" word="Sofies"
lemma="Sofie" pos="prop" morph="GEN"
extra="hum"/>
<t
id="s43_3" word="mor"
lemma="mor" pos="n" morph="UTR S IDF NOM"
extra="--"/>
<t
id="s43_4" word="var"
lemma="være" pos="v-fin" morph="IMPF
AKT" extra="--"/>
<t
id="s43_5" word="sur"
lemma="sur" pos="adj" morph="UTR S IDF NOM"
extra="--"/>
<t
id="s43_6" word="over"
lemma="over" pos="prp" morph="--"
extra="--"/>
<t
id="s43_7" word="et_eller_andet"
lemma="en_eller_anden"
pos="pron-indef" morph="NEU S NOM" extra="--"/>
<t
id="s43_8" word="skete"
lemma="ske" pos="v-fin" morph="IMPF AKT"
extra="--"/>
<t
id="s43_9" word="det"
lemma="den" pos="pron-pers" morph="NEU 3S NOM"
extra="--"/>
<t
id="s43_10" word="at"
lemma="at" pos="conj-s" morph="--"
extra="--"/>
<t
id="s43_11" word="hun"
lemma="hun" pos="pron-pers" morph="UTR 3S NOM"
extra="--"/>
<t
id="s43_12" word="kaldte"
lemma="kalde" pos="v-fin" morph="IMPF AKT"
extra="--"/>
<t
id="s43_13" word="deres"
lemma="de" pos="pron-poss" morph="--"
extra="--"/>
<t
id="s43_14" word="hus"
lemma="hus" pos="n" morph="NEU S IDF NOM"
extra="--"/>
<t
id="s43_15" word="for"
lemma="for" pos="prp" morph="--"
extra="--"/>
<t
id="s43_16" word="et"
lemma="en" pos="art" morph="NEU S IDF"
extra="--"/>
<t
id="s43_17" word="værre"
lemma="dårlig" pos="adj"
morph="COM nG nN nD NOM" extra="--"/>
<t
id="s43_18" word="menageri"
lemma="menageri" pos="n" morph="NEU S IDF
NOM" extra="--"/>
</terminals>
<nonterminals>
<nt
id="s43_500" cat="s">
<edge
label="STA"
idref="s43_501"/>
</nt>
<nt
id="s43_501" cat="v-fin">
<edge
label="fA"
idref="s43_502"/>
<edge
label="--"
idref="s43_8"/>
<edge
label="Sf"
idref="s43_9"/>
<edge
label="S"
idref="s43_506"/>
</nt>
<nt
id="s43_502" cat="v-fin">
<edge
label="SUB"
idref="s43_1"/>
<edge
label="S"
idref="s43_503"/>
<edge
label="--"
idref="s43_4"/>
<edge
label="Cs"
idref="s43_504"/>
</nt>
<nt
id="s43_503" cat="n">
<edge
label="DN"
idref="s43_2"/>
<edge
label="--"
idref="s43_3"/>
</nt>
<nt
id="s43_504" cat="adj">
<edge
label="--"
idref="s43_5"/>
<edge
label="DA"
idref="s43_505"/>
</nt>
<nt
id="s43_505" cat="prp">
<edge
label="--"
idref="s43_6"/>
<edge
label="DP"
idref="s43_7"/>
</nt>
<nt
id="s43_506" cat="v-fin">
<edge
label="SUB"
idref="s43_10"/>
<edge
label="S"
idref="s43_11"/>
<edge
label="--"
idref="s43_12"/>
<edge
label="Od"
idref="s43_507"/>
<edge
label="Co"
idref="s43_508"/>
</nt>
<nt
id="s43_507" cat="n">
<edge
label="DN"
idref="s43_13"/>
<edge
label="--"
idref="s43_14"/>
</nt>
<nt
id="s43_508" cat="prp">
<edge
label="--"
idref="s43_15"/>
<edge
label="DP"
idref="s43_509"/>
</nt>
<nt
id="s43_509" cat="n">
<edge
label="DN"
idref="s43_16"/>
<edge
label="DN"
idref="s43_17"/>
<edge
label="--"
idref="s43_18"/>
</nt>
</nonterminals>
</graph>
</s>
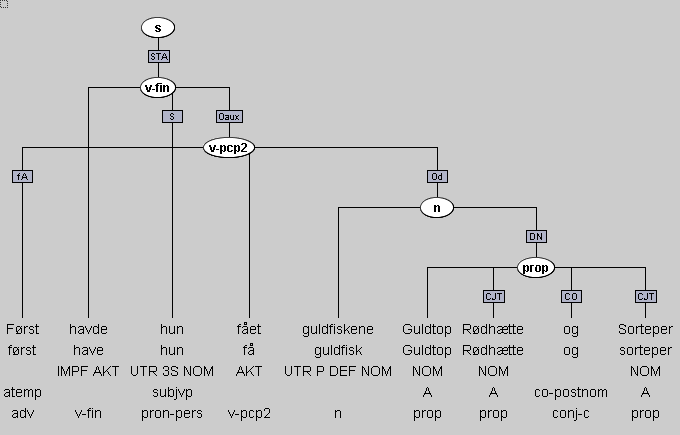
MALT dependency format:^
This format was developed by
Joakim Nivre at Växjö
University. For evaluation purposes and compatibility, VISL data can be
transformed into MALT, using either visldep2malt
(from CG dependency format) or visltiger2malt
(from VISL-tree format).
<sentence
id="s43"
ref="sofie-da43" source="Sofie-da" forest="5/7" text="Når
Sofies
mor var sur over et eller andet, skete det at hun kaldte deres hus for
et værre menageri. ">
<word id=1 form="Når"
lemma="når" pos="conj-s" morph="--" extra="--" deprel="SUB"
head="4"/>
<word id=2 form="Sofies"
lemma="Sofie" pos="prop" morph="GEN" extra="hum" deprel="DN"
head="3"/>
<word id=3 form="mor"
lemma="mor" pos="n" morph="UTR S IDF NOM" extra="--" deprel="S"
head="4"/>
<word id=4 form="var"
lemma="være" pos="v-fin" morph="IMPF AKT" extra="--"
deprel="fA"
head="8"/>
<word id=5 form="sur"
lemma="sur" pos="adj" morph="UTR S IDF NOM" extra="--" deprel="Cs"
head="4"/>
<word id=6 form="over"
lemma="over" pos="prp" morph="--" extra="--" deprel="DA"
head="5"/>
<word id=7 form="et_eller_andet"
lemma="en_eller_anden" pos="pron-indef" morph="NEU S NOM" extra="--"
deprel="DP" head="6"/>
<word id=8 form="skete"
lemma="ske" pos="v-fin" morph="IMPF AKT" extra="--" deprel="STA"
head="0"/>
<word id=9 form="det"
lemma="den" pos="pron-pers" morph="NEU 3S NOM" extra="--" deprel="Sf"
head="8"/>
<word id=10 form="at"
lemma="at" pos="conj-s" morph="--" extra="--" deprel="SUB"
head="12"/>
<word id=11 form="hun"
lemma="hun" pos="pron-pers" morph="UTR 3S NOM" extra="--" deprel="S"
head="12"/>
<word id=12 form="kaldte"
lemma="kalde" pos="v-fin" morph="IMPF AKT" extra="--" deprel="S"
head="8"/>
<word id=13 form="deres"
lemma="de" pos="pron-poss" morph="--" extra="--" deprel="DN"
head="14"/>
<word id=14 form="hus"
lemma="hus" pos="n" morph="NEU S IDF NOM" extra="--" deprel="Od"
head="12"/>
<word id=15 form="for"
lemma="for" pos="prp" morph="--" extra="--" deprel="Co"
head="12"/>
<word id=16 form="et"
lemma="en" pos="art" morph="NEU S IDF" extra="--" deprel="DN"
head="18"/>
<word id=17 form="værre"
lemma="dårlig" pos="adj" morph="COM nG nN nD NOM" extra="--"
deprel="DN" head="18"/>
<word id=18 form="menageri"
lemma="menageri" pos="n" morph="NEU S IDF NOM" extra="--" deprel="DP"
head="15"/>
</sentence>
Transformation Tools:^
The table below provides an
overview of format transformation programs
and filters. The pipe symbol '|' means that the transformation may be
achieved by chaining a number of step-by-step programs. Red tools are
Perl based (Eckhard Bick), blue ones are Prolog based (Søren
Harder). NTN-tools are available through the Nordic Treebank Network.
cg2visl (green) is not one program, but a suite of language dependent
phrase structure grammars and the VISL's open source C++ rule compiler.
| |
CG | CG-dep | VISL | VISL-dep | TIGER | TIGER-dep | MALT-dep | DTAG-dep |
| CG | |
cg2dep depsplicator |
cg2visl (visl-psg + grammar) |
depsplicator | cg2visl | visl2tiger.pl | cg2visl | visl2tiger.pl | tiger2dep.pl |
cg2dep | visldep2malt | depsplicator |
| CG-dep | |
|
|
|
|
|
visldep2malt | |
| VISL | tree2cg | |
|
|
visl2tiger.pl | visl2tiger.pl | tiger2dep.pl | visl2tiger.pl |
tiger2dep.pl | tigerdep2malt |
|
| VISL-dep | |
|
|
|
|
|
|
|
| TIGER | |
|
|
|
|
tiger2dep.pl | |
|
| TIGER-dep | |
|
|
|
|
|
tigerdep2malt, (NTN tools) | (NTN tools) |
| MALT | |
|
|
|
|
(NTN tools) | |
|
| DTAG | |
|
|
|
|
(NTN tools) | |
|
- Copyright 1996-2005 - Privacy Policy - Terms of Use - Report a Problem / Contact Us -
 Balloon Ride
Balloon Ride Danish
Danish English
English Latin
Latin Labyrinth
Labyrinth Arabic
Arabic Bosnian
Bosnian Dutch
Dutch Estonian
Estonian Finnish
Finnish French
French German
German Greek, Ancient
Greek, Ancient Italian
Italian Japanese
Japanese Latvian
Latvian Norweigan,
Bokmål
Norweigan,
Bokmål Portuguese
Portuguese Russian
Russian Spanish
Spanish Swedish
Swedish Paintbox
Paintbox Post Office
Post Office Shooting
Gallery
Shooting
Gallery Syntris
Syntris Wordfall
Wordfall Faroses
Faroses Sami
Sami KillerFiller
KillerFiller Vocabulary
check
Vocabulary
check Filmquiz [fun
only]
Filmquiz [fun
only] Animal Quiz
Animal Quiz Esperanto
Esperanto Pre-analyzed
Pre-analyzed Machine
Analysis
Machine
Analysis Text Painter
Text Painter Greenlandic
Greenlandic Icelandic
Icelandic);){kind=link}